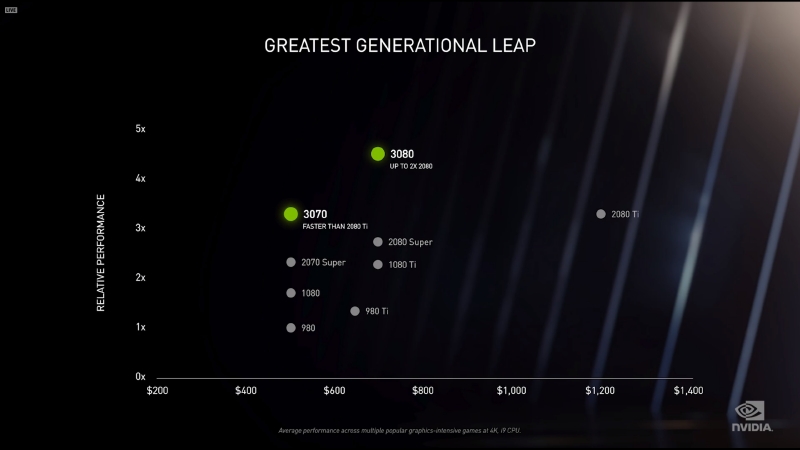
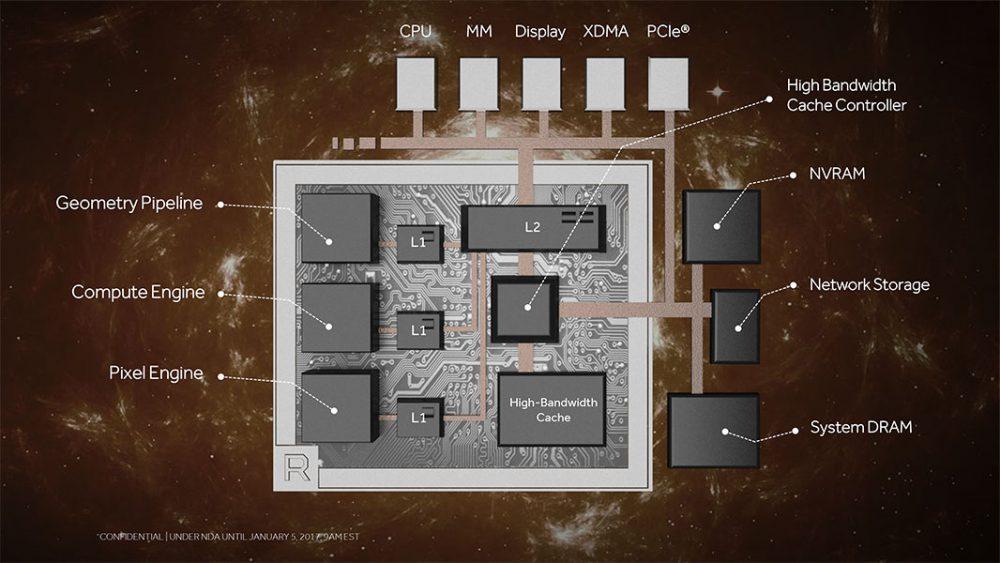
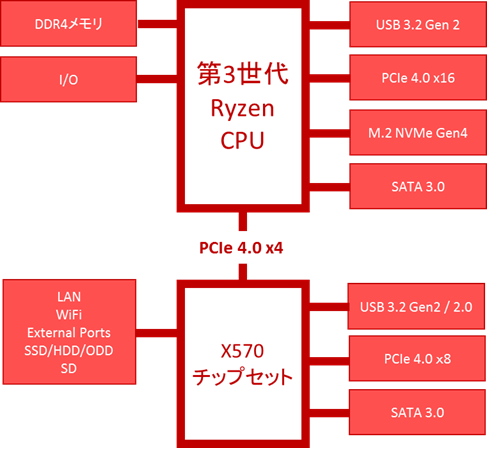
RX 5700XT�̐��\250%�A�b�v�������烏�b�p50%�A�b�v�ł�TDP375W�ɂȂ����Ⴄ�̂��B
Vega64�Ń��L�b�h�N�[���G�f�B�V�����ƒʏ�ł̕������������
������Ă���̌^�Ń��W���������������炶��Ȃ����H
�Q�[��������ӎ������g���Ȃ��ƃ}���`GPU�͓d�C�̖��ʂɂ����Ȃ�Ȃ��Ȃ邩��Ȃ�
���̂ւ�͐ύڕ��@����ł���
>>8 Foveros�����̑ш�͒m���
RDNA2�ɂ�TYPE-C���Ă���邩�ȁH
NV��VirtualLink�Ή����v�b�V������USB-C�iAlt mode�Ή������M����DP�j�������͂���
VirtualLink�Ƃ��Q�t�H�X���ł���قƂ�ǘb��ɂȂ��ĂȂ�����A�قڎ���ł�悤�Ȃ���
RX5000�V���[�Y�������I�ɂ�VirtualLink�̉�H�����Ă���ǁA�R�X�g�̖��ŎE���Ă���Ęb����ˁB
USB4��TB3�x�[�X������virtual link�͂��̂܂܃t�F�[�h�A�E�g����Ȃ���
VirtualLink�̓t�F�[�h�A�E�g�ł�TYPE-C�͗~������
MB�ɕt���Ă���MB��T-C�܂ŃA�E�g�o����p�X��g��
TB3��TB4��USB4��Type-C�݂̂�������S����
�����Ȃ�Type-C�݂̂ɂ���Ă�����
�����S��TYPE-C�ł��������ȁBDP�ϊ�������Ȃɍ����Ȃ����B
�l�W�~�ߋK�i�͂���܂���B�̗p����Ă邩�ǂ����͒m���
������GPU�͋�����3�{�̃i���o�����O��
����[�A����RX5x50�ł���B
���W����GPU�������\�H
MCM GPU�Ƃ������N�\�ȉ��̋Z�p
����܂��g�����ƕ����ɂ�邪��
>>32 >>35 �ǂ���s���L���ł���
MCM�̕����q�[�g�X�v���b�_�ł����ł����Ƃ��Ⴄ�̂�H
>>37 ROME�̎������������z�������
>>40 ��p�̓s����3D�ύڂł���̂�10W�ȉ���������
Rocket Lake-S��TDP125w�̗\����
���m���V�b�N�ʼn��ɖʐςƂ�̂Əd�˂�̂��Ă��̃T�C�Y�̒��ŔM���ɂȂ�ȁB
�M���x���M�c���̈Ⴂ�ɂ��\���̖��̂ق����傫���炵��
�����̋Z�p���Ă��Ƃ�����A���̋Z�p�Ōv��͕̂s�K���ł͂���ˁB
Denon�̐V����AV�A���v�̃j���[�X���āA�V�����Ή������@�\����ƁA���N�ȍ~�̃e���r�ɂ̓A�_�v�e�B�u�V���N(FreeSync)�Ή��̂��o�Ă���ȁH https://av.watch.impress.co.jp/docs/review/review/1264682.html >>47 VRR���Ă������ƃ\�[�X�����@�\�͖�킸�σ��t���b�V�����Ă����ł́c�Ƃ��v�������ǁA���̐�����FreeSync (Adaptive-Sync) ���ۂ���
DP���ᖳ�����炠���܂�HDMI2.1��VRR�@�\
ALLM�͒�C�e���V�[���[�h(�Q�[�����[�h)���e���r�������Ă���Q�[���̂Ƃ��Ɏ����I�ɂ���
AV�@�푤���Ή��ɓ����̂��āAPC�┠���ᖳ�����낤����A�����炭PS5���Ή�����낤�B
HDMI2.1��VRR�͂��ł�XBOX One S/X�őΉ��ς݁BNvidia��HDMI�ł�Gsync Compatible��HDMI2.1��VRR�Ƃ̌݊��炵���B
Freesync�͌��X�f�B�X�v���C�|�[�g�����̋@�\������
56CU�ł��̑傫���Ȃ�80CU��bignavi�ł�400mm2���炢�ōς݂������ȁB >>56 >>56 �\�z��80CU��505mm2����������
�ł������ꂾ��3070�Ƃ������\�㋣�����Ȃ����Ċm�肵�Ďc�O����
�n�C�G���h��g�b�v�������낤���A
>>61 >>61 RTX3090��1500�h���Ŕ����Ă��܂��̂�
BigNavi�͍Œ�ł�5700XT�̔{�̐��\�ŁA���i�͑���$899��999���낤��
>>66 ���b�p������1W�ӂ�̃p�t�H�[�}���X��1.5�{����
>>67 >>62 ���b�p50%�A�b�v�́AXSX�̒ʂ�perf/clock��25%�Ƃ��Ďc��̓v���Z�X�V�������N�ɂ��
�@�\���␢�オ�n�b�L�����Ȃ�����Ȃ�Ƃ��E�E
>>71 AMD�uGTX 950��60%����d�͂œ������\���o�����Č�������I�v
��������d�͂�60%�̐��\�Ɍ�����
60%�Ƃ����ƌ����I�ł́A���ɑ����3050���ゾ�낤��
�ł��炟�I https://pc.watch.impress.co.jp/docs/news/event/738337.html https://pc.watch.impress.co.jp/docs/topic/review/1014381.html >>71 �v���Z�X��������ǂɂ���������͍��N���b�N���������d�͉���
���C�g���R�A�̕��s�����v��߂ăQ�t�H�݂����ɒP�ƃR�A�ɂ��悤��
>>80 >>81 4 Texture or Ray ops/clk per CU�́hor"�͂ǂ�����������낤�� ���߂�B���s�����ł�����ď����Ă�� �Q�t�H�̃��C�g�����N�\�G��������C�ɂ����
>>80 �ǂ��������Ă�bignavi��RTX3070�Ō������Ă��܂�������Radeon��apu�ōׁX�Ɛ����c�邵���Ȃ����낤
�o�Ă��Ȃ��̂ɎY�p�m�肳��Ă�����
2�{���炢�R�X�p���悭�Ȃ�Ȃ炢���낤���ǂ˂�
�ւ��A3070��3080��荂���\�Ȃ�
�v�W������Bignavi�ɂтт���3070��104�ڂ�����ł���H
94 Socket774 2020/08/21(��) 09:55:35.18
>>91 http://pc.watch.impress.co.jp/docs/news/1271807.html >>84 >>93 ���N��28nm��BigBulldozer2���o�邩��Haswell���b�m�肾��w
>>92 BigNavi���Č����Ă��A�����ɂ�RDNA2�Ƃ��������ĂȂ����A���[�N�ł�Navi21�ANavi22�ANavi23�ƌ����Ă邮�炢��
EU�̃Q�[���@����K��SRI���A�C�h��70W�ȓ�������啝���͂Ȃ����낤��
RTX�̓T���X�������ŃN�I���e�B�Ⴂ����t�]�ł���\���͂����
>>101 �t�]������AMD�����邩����قǂɂ��������
���\�ł͂ǂ��������Ă����ĂȂ�����
���\�ł͕����ĂȂ���
NVIDIA�̃��C�g�������Ȃ̂͂Ȃ�łȂˁB
>>106 Bignavi����3�X���ATDP 350W���炢�Ŏ��܂�́H
>>109 BigNavi��250-300W����
���b�p�㏸��GCN��Navi10�Ɠ�����50%�Ə㏸�Ȃ̂�
���b�p�Ȃ�ăX�C�[�g�X�|�b�g�Ŏ咣��������K���������i�ɔ��f����邩�́c�c
���\�O������ɗ₦��Ƃ�������]������Ⴕ�Ȃ�
RDNA��IPC�͂قƂ�ǐL�тȂ��Ǝv����
HOT CHIPS��XBOX�̔��\�Ō�����
�����炭one X��ł���
MS�̍u���Ō����O����͓��RXbox�̂��Ƃ����Ȃ����
���b�p50%�A�b�v����225W��5700XT��2�{�̐��\��300W
20TFlops���x����Xe��MCM�\����44TFlops�ɏ��ĂȂ���˂�
>>118 ���A�Ă���������������APS5�͖����̒��Z�p�Ǝv���Ă�l��
�͂��H�H
���������ă��b�p��IPC�̋�ʂ����ĂȂ������H
���ǁARDNA��CDNA��GCN���̃o���G�[�V�����������ȁBdGPU�͔ӔN�̓I�݂����Ȃ��Ă�
>>124 >>123 IPC���㏸�����g���㏸�ɂȂ���̂͂Ȃ�ŁH
>>126 RDNA2�ł͕ێ�����Wave�������炵�ăX���b�h���\�����߂Ă�炵��
>>129 >>130 >>131 >>133 RDNA2�ŕێ�����wave�����炵���̂́A
>>134 >>127 �Ƃ����Ă��v������ >>136 �ɒ[�Ă������uIPC���オ������A���̕����g�����グ�₷���v���Ă������X�������I�ɂ͂ނ���t������Ē[�I�ɐ������Ă��
>>138 OoO�Ƃ��W�Ȃ��P���ɃX�����ȉ�H�\���Ȃ�N���b�N�̂��y�ɂȂ�Ƃ�������
>>135 >>125 BigNavi��CU�����ł͂Ȃ���ROP�͑����Ȃ��̂��H
�R���ł���������
BigNavi�Ń������o�X��ROP��{�������邾�� >>145 �����Ă鑤�Ȃ�Ƃ������A�����Ă鑤���o���ɂ��݂��Ăǂ�����̂��Ďv����
AMD�̎v�f�Ƃ��ẮA�Œ�@�\��ROP�ˑ������炵�AGPGPU�ɂ�鍂�x�Ŏ��R�x�̍����O���t�B�b�N�����𑝂₵�āA�O���t�B�b�N���̂̃N�I���e�B���グ����
�������g���ĂȂ�CU�ɐ�p�̖��ߑg���ROP�̑�֏o����l�ɂ��Ă���
>>150 GPGPU�d������GCN���ジ���ƌ��������Č��ǂ͏���Ă��ĖႦ�Ȃ����������
�����Nvidia�����Ȃ�����PC�Q�[�����[�J�[�����Ȃ����낤
CU���͕̂ς���ĂȂ������ >>151 �C�O�̏��PG142-0��BigNavi�łقڊԈႢ�Ȃ���
�܂肱���������Ƃ�
3070�ɒl�i�E���\�Ŋ��s�H����d�͂��炢�������ɂȂ肻���Ȃ�
7nm+��BigNav���T���X����8nm�i10nm�̉��ǁj�ɕ�������p��
>>158 �Q�t�H�~�K������
>>160 NVIDIA��12pin���m�肵������Ȃ�
12pin��FE�����ˁBAIC������3090�̃��t�@�����X�J�[�h��8pinx3�B
12pin��8pinx3���ǂ��������M�m�肾��
12pin�͈ꉞ12V/9.5(8.5)Ax6=684(612)W�܂ł�����8pinx3�Ȃ�450W�܂ł����B
MI100�Ƃ�500W���炢������Ȃ��́H
MI100�́ACU120��TDP200W�ƌ����Ă�B
>>165 ����HPC�̑I�ʗ������r�f�I�J�[�h�ɂ��Ă邩��ł���
MI100�̃e�X�g�T���v����200W����������
��ʌ����ƃf�[�^�Z���^�[�����Ƃ��ׂĉ�������������
MI�̕��͕ʃ_�C�ɂȂ������牽�Ƃ�
>>149 >>175 >>176 Radeon��2020�N�����̊��Ԍ��肷���dGPU�̃V�F�A20%�������Ȃ��ĂĒN�������ĂȂ����
>>177 �[�������V�F�A�����Ă�GCN�͎��s����Ȃ������������Ƃ������Ӗڂ��܂�����̂�
�Q�[����GPGPU�𗼗����悤�Ƃ������ʂǂ������V�F�A���Ƃ�Ȃ������I�`
�h���C�o�[���܂��}�V�ɂȂ����̂�GCN�̂��������Ǝv��
GCN����́A�J���\�͂��ׂ������Ƃ��U���Ȃ��������������A��������AMD�{�̂������I�ɂ���ς���������Ȃ̂�
�ꉞ�AHPC��T�[�o�[�ɂ��w�e���W�j�A�XAPU�Ԃ����ޗ\�肾������
>>180 GCN�̂�������PS4/XBOXone/PS5/XBOXsX�̗̍p����������Ă��
>>185 ����GPGPU�̎��ザ�ᖳ���Ȃ�������
CDNA����̂ɒ��r���[��GPGPU�ɐF�C�o���Ă邩��A�C�V���Ƃ�����������
NV�̃f�[�^�Z���^�[��������Ɣ�ׂ�Ƃ܂��܂������ǂ�
>>187 >>189 >>190 AMD�͐��N����CPU������GPU�X�g���[�W��
AMD��Intel���Ǝ��o�X�̓Ǝ��v���b�g�t�H�[���ŃG�R�V�X�e��������Ă�������ANvidia�������n�u���Ă���
�ꉞNVlink�Ōq����IBM��POWER�����邯�lj_�s����������
>>194 �����Ă��^�_�̈��������ł���������
CPU�����Ȃ��z���C���R�l���������Ă̂���
>>199 Linus��NVIDIA�ɒ��w���Ă��̂������Ǝv���Ă�
����AMD��GPU�͂����Ă͍����I�ɃA����������Ńh���C�o���F�X����ĂȂ��ł���B
PS4�㔼��EPYC�ʼn҂������v��H���Ԃ��Ă���B
����ǂ�����ĐH���ׂ�����H
���R�͂Ȃ���?
hotchips��valve��LLVM�o�b�N�G���h�@�\�Ɠ�����
>>207 �Ƃ��������Ń`�b�v�̃J���t�@�����X��Valve���\�t�g�E�F�A�̘b�������
>>206 x86���ւ����̂͑��Ђ�����ɂ�����Ȃ�����A�Q�[���@��APU��AMD���J������AMD��TSMC�ɐ����˗����āA
�Q�[���@���[�J�[�̔����ɏ]���đ��邾��������
>>213 ���̕ӂ�Intel���ǂ��܂ŋ����Ă�Ƃ����C�Z���X���ǂ��Ȃ��Ă邩������
���C�Z���X���͋C�������Ă�B
>>216 >>218 >>219 >>220 >>220 �\�j�[��AMD�ɔ�������TSMC�Ő���
RTX 3090��RTX 2080Ti����100%����������Ă邶��Ȃ���
RTX3000�V���[�Y�̏�ʂ��s��3�X���b�g���H���₪�邩��2�X���b�g�Ɏ��߂Ă�����Big Navi������
>>226 >>222 >>224 >>228 >>229 >>155 >>224 >>228 >>230 >>232 �������Ⴂ���Ă�̂��m��� >>233 >>231 RTX3X�����
>>235 >>236 �����������v
>>239 ���[�N����z��������炿���Ɛ��\���킹�Ă����
������������ɒl�����Ƃ��v�W���������킯�Ȃ���
>>238 >>244 AMD�����������̂̓V���R���_�C�̊J���Ɛ����ŁA�p�b�P�[�W�͌_��O���낤 �����A���������Q�[���@��M/B���t���� >>245 ���X�O�O�������ǐ��Y�n�̍����Ryzen�Ɠ����}���[�V�A https://www.4gamer.net/games/990/G999024/20160908148/ >>248 >>241 >>251 >>251 MI100���R���V���[�}�ɍ~�낵��10���Ŕ���
2000��3000�̓��b�p1.1�{ https://wccftech.com/report-nvidia-geforce-rtx-30-gpus-to-be-in-short-supply-until-2021/ DF�̓��悪�悭�킩��Ȃ�
Nikon DF�͌��ڂ��������甃��Ȃ������B
�܂�3000�V���[�Y���b�p�͂����������ƂȂ����ǁA�~�h���̃R�X�p�͂��Ȃ�悭�Ȃ��Ă�ˁB
RDNA2�������
�t����
��U�����Ƃ͎v�����T�˓����ӌ���
���v����̃J�M�͂��������ǁA���\����̉����̓_�C�ʐϑ傫�����ăG���W�������ςނ��Ǝv��
Ampere�Ȃ�7nm����Ȃ��ăT��8
RTX3000�͏����[���璴�r�b�O�_�C�Ƃ�7nm�����r�߂����A����Ƃ�Nvidia�̋Z�p�͂��ߐM�������Ă�̂�
>>265 ����bignavi��AIB�Ńx���`�Ă�i�K����
>>267 RTX2000��RTX3000�̓��b�p10-20%�̉��P
>>269 >>264 �܂��A����AMD�͌�o���o���闧�ꂶ��Ȃ����ǂȁ[�B3000�V���[�Y�J���ꂽ��ɒǂ��t���Ă��q�D����
�T���\���������Ă����s���v�f�ȊO���Ă�v�f�Ȃ���
���̏�AMD�͂���܂肵��������Ď��͂������������������
>>275 �܂�Zen3���_���}�����Ă邩�玸�s�Ƃ������Ƃ���
�m����SAMSUNG8nm�ɑ���TSMC7nm��GPU��������
RTX 2000�Ɉ���������Ă��Ƃ����3000�ł���Ɉ��������ꂽ�����Ȃ̂ɂ�
CDNA�Ɠ����悤��CU�\�����Ă���bignavi��10000�R�A�����Ă�\�������������
>>275 AMD���R�X�p���A�s�[�����鎞�͐��\�����d�͂ł��Ȃ�Ȃ��Ƃ�
����AMD���v�W���������|���鎞�オ����̂�
�N���ɂ�Zen3�����ƃI�}�P��1�t���Ă���L�����y�[���ł����Ȃ��Ƒʖڂ���
����VR�x���`�̂��̃X�R�A��M���Ă���
>>283 �t����ł����Ă����ɂȂ��̂ł�������̉\��
CU80�ɂ������ė��_�l��RTX3070�ɕ����Ă邩�炨������͊m�肵�Ă���Ǝv��
RTX3000��CUDA�R�A����TFLOPS�̒l�͌v�Z���@��ς���������
Volta�ȍ~FP32��INT32���������s�ł���悤�ɂȂ��Ă��̂��AFP32�̃R�A����{��
Ampere���N���͋������i���A�������N�����Ƒ卷�Ȃ��Ƃ����
RTX�̒lj���INT��FP���g���ɂ͐�p��API���g��Ȃ��Ɩ���
BigNavi $549������
�^�Ԃ���s���Ȃ̂ɉ��i����������킯�Ȃ�����A�z
BigNavi����ȂɈ����̂��ˁB����h���C�o�̃`���[�j���O�͂܂��A���ł��傤���ǁB
GCN�ȍ~��DX12���^�[�Q�b�g�ɍ�荞��ł邩��ADX11��GameWorks���ƃC�}�C�`�ɂ����Ȃ��
RTX�̎d�l���Ă܂��������[�J�[���������Č����Ă邩��
CU���̍\�����悾��
GCN��RDNA�����Z�펩�̂͂��̂܂g���Ă�Ƃ������Ƃ́A�����獂�����Ȃ낤
�����_�����O���\��������directstorage���T�|�[�g����̂����C�ɂȂ���
DirectStorage��Vega���瓋�ڂ��Ă�HBCC��DirectX�ł��� ����̓V�X�e��RAM�̈ꕔ��VRAM����ɂ��炤�Z�p������ʕ��ł́H
���g�Ƃ��Ă�DMA��GPU�Ƀt�@�C���̓W�J�����s������API�ł���
����GPU����
CPU��SSD�̐ڑ��͂ǂ��Ȃ�낤
>>311 �ăA�}�̒l�i�炵��
>>313 >>313 >>311 AM4����NB����Ȃ�CPU (IO �`�b�v���b�g)�o�R >>318 >>314 >>320 �������s�b��Ȃ������r�߃v�ł����Ȃ�
>>321 >>321 �ϑz�Ŋm��Ƃ��Q�t�H�~���K�����Ȃ�
>>325 �\�b�ɐU��ꂷ���B
�������i���Č����ŏo���Ă�����
BigNavi�͂܂����\������ĂȂ��̂ɖϑz�����͐����ȃT�T��
BigNavi�A���i���\�O��Big�l����
�����P���Ƃ��W�Ȃ��Q�t�H�̃x���`�Ɠ����x���̐��i�����������l�i�ŏo�������Ȃ�
EPYC�i�I�pCPU)>>>RyzenAPU(�m�[�g)>RyzenCPU�i�f�X�N�g�b�v)>>>Radeon
CDAN�Ƃ͂���NV�Ɋ��������̂�
nv�݂�����RNDA1��GPU�̍ő含�\�Ɠ������\���̏���d�͂�2/3�Ń��b�p50%�A�b�v�Ƃ����������Ȃ���ˁB
> CDAN�Ƃ͂���NV�Ɋ��������̂�
���������Ӗ��ł�INTEL Xe�ł������Ă܂��˂�
>>335 >>337 MI100��FP32�̉��Z�\�͂�A100�̔{�ȏ�Ȃ̂��f�J��
�X�p�R�����Ă̂͒ᐸ�x�����ᖳ�������
AMD�̃G���^�[�v���C�Y������GPU�̐��\��NVIDIA�ɏ����Ă�̂͂킩������
�J���͖{�C�o���Ă邼�A�}�[�P�e�B���O�͒��蔲��������
CS�����ɍ�������̂��ł����e�[���ɏo���Ă�Ƃ����v���Ȃ�
CS�������Ă��Ƃ͎�����Q�[�������ɒ������A���œK���Ƃ������Ƃ���
CS�œK���Ȃ��PC�Q�[���ɂȂ�ƑS���W�Ȃ��Ȃ邯�ǂ�
Intel�̍œK���̓_��������Radeon�̍œK���͗ǂ�����
���Ђւ̍œK�����Ă�葼�Ђɐ��\�o�����Ȃ��̂��d���݂����Ȃ��Ƃ����Ɖ����ł��Ȃ�
>>344 ���ǁAGCN����̓V�F�A�ł��W�����ł����s����CS�@�ɓ�������ʼn��Ƃ������c���������̐���Ƃ��������Ȃ���
>>349 ����������nvidia�͏o�������̂��̂���邵���\�������̂��
>>351 >>352 >>355 >>354 >>356 >>356 VR���̂��G���X�[���������A�ڑ��̔ώG���͉����������m����Ȃ������Q����Ȃ�����
>>360 �܂�AMD���ƊE�̑��������������̂�
>>360 ���\�������玸�s�L��������������Ȃ�
USB4��TB�x�[�X�ɂȂ�̂ɗ�TB��VirtualLink���c��Ǝv���Ă��̂�
�Ƃ͌����A�����o������nVidia���A2060�ȉ��ɂ͕t���ĂȂ�����ȁB >>363 USB4�̓��j�o�[�T���P�[�u���ōő�2m������ȁB����ȏ�͌��P�[�u���ɂȂ��B
Microsoft�A�uXbox Series S�v�𐳎����\ https://game.watch.impress.co.jp/docs/news/1275718.html >>369 >>369 >>371 ����ʂ�NVIDIA�͏����ĂȂ�
��������AMD�̃|�e���V������rx5700XT�̎��_��RTX2080ti������250w�܂ň����L����
400mm2�̃r�b�O�_�C���T���X�����܂Ƃ��ɗʎY�ł���킯�Ȃ�����
>>375 400mm2��3070�̂���
RDNA2�͂Ƃ������AbigNavi�G�O���S���ĉ\���邶���B���ۂ�DB�ɏo�ė��ĂȂ���
�����Zen3���ɔ��\���邩��ȁARDNA2�̏��Ȃo���킯���Ȃ�
3080�̃x���`�Ŏn�߂�����2080Ti����25%�O��݂�������
AMD�ŃQ�[�~���O�\�����[�V�����ƃ}�[�P�e�B���O�S�����Ă�l��
3080�̓Q�[���ȊO�̕�����2080��2�{�ł����̐S�̃Q�[����1.5�{���炢�ł����Ċ�����
RDNA2�ŃQ�[���̃��b�p�͋t�]������
����Bignavi�͂��߂�Ȃ������\���邩������Ȃ�����ق�bignavi�͎Y�p���������Č��_�ł����Ǝv����
>>370 >>371 Big Navi�͗��T�o��Apple Watch��S6 GPU��葬���̂͊m���炵����
nVIDIA��DLSS�Ƃ�VRS�Ƃ�Mesh shader�Ƃ��`��R�X�g��������Z�p�Ő�s���Ă����ȁB
�㏞�L��ŕ`��R�X�g�������Ă��Ӗ����Ȃ�
>>373 VIDEO >>383 >>373 >>392 �f�[�^�ʂ͉��Ƃł��Ȃ邾�낤
>>394 >>396 SM������̕ʂɃR�A���͑����ĂȂ�������BTuring��INT32��p��FP32�ƌ��p�ɂȂ��������B
�o�����X���������ς���Ă�
RTX3000�̍ő�̉��Ǔ_��FP32�̔{�������ǁA���ꂪ���̂��߂Ȃ̂����C�}�C�`�������
>>401 >>401 FP32��{�����Ă����ۂ�1.2�{�Ƃ��������サ�ĂȂ�
Int32���V�F�[�_�[�Ŏg������
>>401 �܂��A�M���Ȃ�͕̂����Ă��̂ł���ȃG�A�[�t���[�l���čڂ��Ă����낤���ǁB
�R�X�g�d����Samsung 10nm�I�̂�����������
�ǂ������Ƃ�����GPU�ɌՓO�݂����Ȃ̂��������ĂĂ��������C�ɂȂ肷����
AMD���Ȃ��Ȃ����j�[�N�ȃG�A�[�t���[���
>>408 GPGPU��_���؎�`��GCN�̉��ǔłł����Ȃ��̂��I�悵����
�n�C�G���h�Ń������o�X��256bit�����Ȃ��̂��H
3nm+�܂ł�����
�ꐶ�����B�]�T����Ȃ�N���b�N�オ�邩��B
AMD�͌���Twitter�ɂ����āA����CPU�uZen 3�v��10��8���A����GPU�uRDNA 2�v��10��28���ɔ��\����Ɨ\�������B
���f���[�U�[�ɂ̓G�L�T�C�e�B���O�A�Q�t�H���[�U�[�ɂ͈��@�������낤��
>>421 Bignavi��PCB���OEM�ɖ����ɒ���ĂȂ����班�Ȃ��Ƃ��Y�p������N����肽���Ƃ͎v��Ȃ����ǃI���t�@���o�Ă�1���ȍ~�ŔN���͕s�\
>>421 �C�O�ł�ZEN3�͂��Ȃ���҂���Ă邪BigNavi�͒N�����҂��ĂȂ��悤�ȏ������݂���
RDNA2���X�y�b�N��RTX3000�ɕ�����C�͑S����������A�l�i�ƃ��C���i�b�v�̔��\�҂�
>>427 �`�F�b�J�[�{�[�h�ł��������ǁA4k�����_�����O�ɍS�莝���Ă�l�������������
>>428 INT4/INT8�n�̉��Z���߂�Navi14����Ή����Ă�
DX12_2�̋@�\�̓t���T�|�[�g�m�肵�Ă邩��XsX�̋@�\�������Ƃ͎v���Ȃ���
>>431 DLSS�͗����Ƃ��Ă�TAAU+DL�݂����Ȃ��ˁB VIDEO �V�F�[�_�[���̂̃J�X�^���͖ʓ|�L�����Ă��Ȃ��ł���
DLSS2.0��DLSS1.0+RIS�̃p�N���ł���